Or how Python C module can boost your code
Python is quite a powerful language, however, it has its limitations like GIL. On the other hand this flexibility lets you go around a lot of those limitations with some nice hacks. Today I’ll show you how to write your own Python C module. As always, you’ll find the link to the example in my Gitlab at the bottom so that you can play around with it yourself.

Goal
The aim is to write a program that sums n consecutive numbers. I will compare efficiency of code written in pure Python with the same algorithm implemented in C.
The Python code
First, I’d like to show you how it can be done using pure Python.
def py_sum(number_of_steps: int) -> int:
i = s = 0
for i in range(number_of_steps):
s += i+1
return s
We have a loop that increments a counter until it reaches the number user has given and a variable used to store the sum result. I know this can be simplified with sum(i for i in range(1, n+1)), but I want to avoid using builtins for the sake of presentation.
Let’s do this in C.
C Equivalent
The only differences here are the need to use types (I’ve gone with unsigned long) and a different loop definition.
unsigned long sum(unsigned long numberOfSteps){
unsigned long s, i;
s = 0;
for(i=0; i<numberOfSteps; i++)
s += (i+1);
return s;
}
Now the fun with Python and its C modules begins. First of all, we need to wrap the sum function around something that is actually callable through Python.
static PyObject* method_sum(PyObject* self, PyObject* args) {
unsigned long countOfNumbers;
if(!PyArg_ParseTuple(args, "k", &countOfNumbers)){
printf("# FAIL\n");
return NULL;
}
return PyLong_FromLong(sum(countOfNumbers));
}
The method_sum is an interface between Python and modules in C (although we’re going to call it through a different name). It returns a single PyObject and accepts two of them as arguments. The *args is an array of arguments actually passed to the function. Since everything in Python is an object, and specifically a PyObject, we need to perform some conversions. PyArg_ParseTuple handles converting Python types to C types and "k" says that an unsigned long is expected. You can check out other types here. If it succeeds, sum() is called and the result is converted again to Python’s int or long. Those two differ between Python 2 and 3:
>>> type(1) <type 'int'> >>> type(1L) <type 'long'>
Next step is to register the function in the module and configure the module itself.
static PyMethodDef SumMethods[] = {
{"sum", method_sum, METH_VARARGS, "Calculate sum of n numbers."},
{NULL, NULL, 0, NULL}
};
static struct PyModuleDef summodule = {
PyModuleDef_HEAD_INIT,
"sum",
"Calculate sum of n numbers.",
-1,
SumMethods
};
PyMODINIT_FUNC PyInit_summer() {
return PyModule_Create(&summodule);
}
The first array structure is used to define methods within the module. The first argument is the name under which the method is accessible. Second is a pointer to the function, then goes some information describing how the arguments will be accessed and finally a docstring. Second entry in the array consists of empty values, because there is no len() in C. The program needs somehow find out that it has gone through the entire array, therefore putting NULL values that can’t contain anything meaningful other than “DEAD END” message is the only sensible solution.
Next structure defines module itself. It holds necessary structure members, name of the module, docstring, information for subinterpreters and a reference to method table.
The last method is used to actually create module. The part after underscore is used to locate it and the PyModule_Create() takes a pointer to the structure defining the module. We’re almost there. The last step is to create setup.py file, compile and use.
from distutils.core import setup, Extension
def main():
setup(
name="summer",
version="1.0.0",
description="Calculate sum of n numbers.",
author="gonczor",
author_email="",
ext_modules=[Extension("summer", ["summermodule.c"], extra_compile_args = ["-O0"])],
)
if __name__ == "__main__":
main()
Here we use setup() to configure the build process. It’s important that you notice that apart from metadata, name of files , there’s extra_compile_args setting.
C optimization
Let’s run python3 setup.py install without the extra_compile_args and look at what arguments does the compiler get.
→ python3 setup.py install # ... clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk/usr/include -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers -I/usr/local/include -I/usr/local/opt/openssl@1.1/include -I/usr/local/opt/sqlite/include -I/usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7/include/python3.7m -c summermodule.c -o build/temp.macosx-10.15-x86_64-3.7/summermodule.o creating build/lib.macosx-10.15-x86_64-3.7 clang -bundle -undefined dynamic_lookup build/temp.macosx-10.15-x86_64-3.7/summermodule.o -L/usr/local/lib -L/usr/local/opt/openssl@1.1/lib -L/usr/local/opt/sqlite/lib -o build/lib.macosx-10.15-x86_64-3.7/summer.cpython-37m-darwin.so # ...
What you can see is the optimization flag -O3 which is passed. It tells clang perform an aggressive optimization. Because our example is very simple, the compiler can shorten the calculations to adding numbers at the end of ranges and multiplying by the half of the number of the steps to perform. Assembly of such compilation is following:
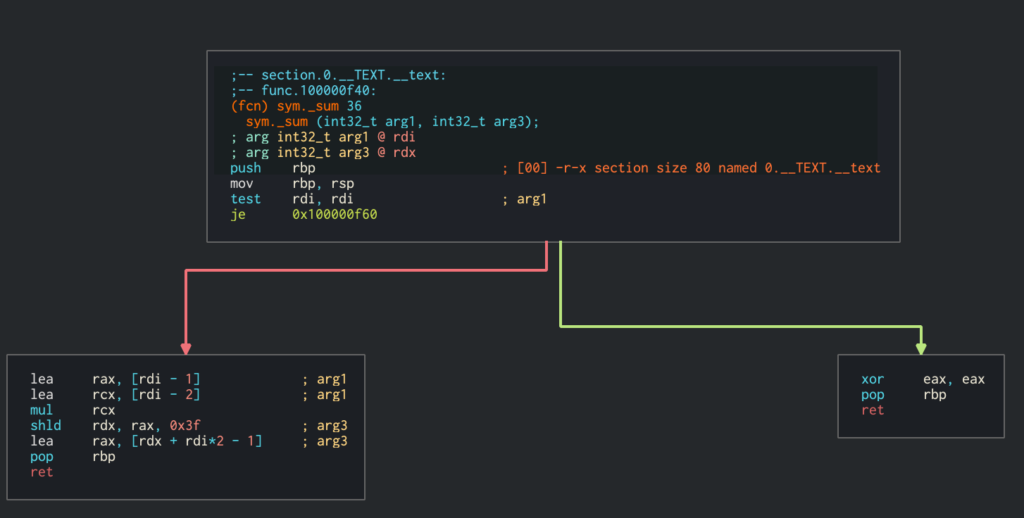
There is no loop here. To add it, we need to lower the optimization with -O0 flag.
→ python3 setup.py install clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk/usr/include -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers -I/usr/local/include -I/usr/local/opt/openssl@1.1/include -I/usr/local/opt/sqlite/include -I/usr/local/Cellar/python/3.7.6_1/Frameworks/Python.framework/Versions/3.7/include/python3.7m -c summermodule.c -o build/temp.macosx-10.15-x86_64-3.7/summermodule.o -O0
You can see the additional flag at the end. The disassembled code will now show a loop through all the values:
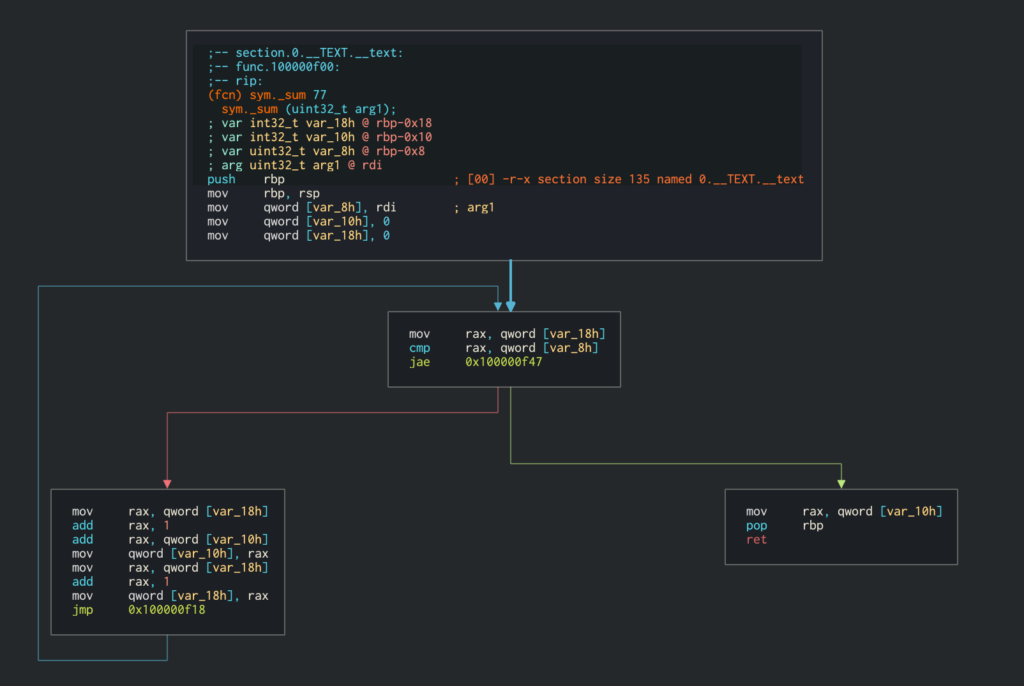
This way both Python and C code will do the same steps to arrive at the result (at least from high level perspective).
Comparison
Let’s now run both examples. Test function is following:
import sys
import time
import summer
try:
COUNT = int(sys.argv[1])
except (IndexError, ValueError):
print('Usage: python3 main.py <count of numbers to sum>.')
sys.exit(1)
def py_sum(number_of_steps: int) -> int:
i = s = 0
for i in range(number_of_steps):
s += i+1
return s
print(f'Calculating {COUNT}')
start = time.time()
result = summer.sum(COUNT)
stop = time.time()
print(f'summer.sum({COUNT}) = {result}\tCalculated in {stop-start}s')
start = time.time()
result = py_sum(COUNT)
stop = time.time()
print(f'py_sum({COUNT}) = {result}\tCalculated in {stop-start}s')
Let’s run it for 1 and 10 million numbers.
→ python3 main.py 1000000 Calculating 1000000 summer.sum(1000000) = 500000500000 Calculated in 0.002355337142944336s py_sum(1000000) = 500000500000 Calculated in 0.09217596054077148s → python3 main.py 10000000 Calculating 10000000 summer.sum(10000000) = 50000005000000 Calculated in 0.023875713348388672s py_sum(10000000) = 50000005000000 Calculated in 0.8099520206451416s
As you can see, the C version is about 40 times faster even after we’ve decided to get rid of the optimization, therefore you should get the idea why it’s worth to write a Python module in C.
Bypassing the GIL (Global Interpreter Lock)
While doing simple arithmetic operations and implementing some algorithms in a way that is faster is definitely something worth struggling (at least in some cases), there’s another big gain from this approach: the ability to get around Python’s GIL.
CPU-bound Tasks vs. IO-bound Tasks
Before we begin, let me explain a difference between two common types of bottlenecks we have in programming.
CPU-bound tasks are tasks that are limited by the capabilities of the processor. They would run faster if they had more processor time (for example there would be fewer other tasks in the operating system, or the tasks would be privileged) or the processor would be faster.
IO-bound tasks are tasks that loose a lot of time waiting for something to happen. This can be a disk read/write operations (like handling files by databases), waiting for network connections etc.
You can think of the former as of a person who wants to reach a certain point and can’t do it quickly because the car they have is too slow. The latter would remind a person who also wants to get to a certain place, but has to wait for other people, for traffic lights etc.
Your operating system assigns certain amount of time to each task (a process or a thread). The process can then do certain calculations until the time runs out. Then the process is suspended and has to wait again to get the time assigned. However, when it stops in order to wait for the IO operations to happen, the time does not run out and it can resume when the IO operation is finished. While it waits other tasks may become active and do their stuff. This is called “context switching”.
What is GIL
Python has the ability to run multiple threads, but there’s one significant limitation to it: only one thread can execute Python code at once. While this isn’t a big deal where we are spending a lot of time waiting for external resources (like in web applications’ case where a lot of time is consumed eg. by database operations or handling static files), when tasks that are heavy on CPU are considered, this can be a disaster.
Consider the following example of two threads that do some calculation-heavy operations. First is limited by GIL and the second is not.


As you can see the calculations are faster if the GIL is not present. If we have an algorithm that can be parallelized we want to be able to have true multithreading capabilities. Note that if the idle part would be a part of the processing (because output would, for example, need to be saved) there would be no difference.
Splitting into Threads
Let’s see what happens if we try to perform the calculations in parallel in order to gain speed. The threaded C code is following:
#include <Python.h>
#include <pthread.h>
void* sum(void *argp){
unsigned long *stepsFrom = (unsigned long *) argp;
unsigned long *stepsTo = (unsigned long *) (argp + sizeof(unsigned long));
unsigned long s, i;
s = 0;
for(i=*stepsFrom; i<*stepsTo; i++)
s += (i+1);
return (void *)s;
}
static PyObject* method_sum(PyObject* self, PyObject* args) {
unsigned long countOfNumbers;
if(!PyArg_ParseTuple(args, "k", &countOfNumbers)){
printf("# FAIL\n");
return NULL;
}
// Split summing into threads
unsigned long firstStepsHalf[2] = {0, countOfNumbers/2};
unsigned long secondStepsHalf[2] = {countOfNumbers/2, countOfNumbers};
void *result1, *result2;
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, sum, firstStepsHalf);
pthread_create(&thread2, NULL, sum, secondStepsHalf);
pthread_join(thread1, &result1);
pthread_join(thread2, &result2);
return PyLong_FromLong((unsigned long)result1+(unsigned long)result2);
}
There’s a little bit type casting in order to get the desired result, but the clue is that now we sum up two halves of the numbers in two threads. Equivalent Python is following:
def py_sum(number_of_steps: int) -> int:
with concurrent.futures.ThreadPoolExecutor() as executor:
thread1 = executor.submit(sum_thread, 0, number_of_steps//2)
thread2 = executor.submit(sum_thread, number_of_steps//2, number_of_steps)
result1 = thread1.result()
result2 = thread2.result()
return result1 + result2
def sum_thread(start: int, stop: int) -> int:
i = s = 0
for i in range(start, stop):
s += i+1
return s
While it definitely excels in simplicity, it will suffer from the inability to make computations faster. Let’s again try it out with 1 and 10 million numbers.
→ python3 main.py 1000000 Calculating 1000000 summer.sum(1000000) = 500000500000 Calculated in 0.0012197494506835938s py_sum(1000000) = 500000500000 Calculated in 0.08748507499694824s → python3 main.py 10000000 Calculating 10000000 summer.sum(10000000) = 50000005000000 Calculated in 0.012545108795166016s py_sum(10000000) = 50000005000000 Calculated in 0.826207160949707s
As you can see, with an adjustment for the thread management, type parsing, the fact that this experiment is statistically insignificant etc., the C module code has fallen from about 0.0024 and 0.024 to 0.0012 and 0.013 which means it’s now about 2 times faster, while the same code written in Python did not gain any speed. My guess is that if this experiment was conducted more carefully, we could even observe an increase in the execution time since threads need time to create and synchronize.
Final thoughts
One of the pain points of Python is the limited ability to take an advantage of threading. If someone wants to perform operations in parallel, they need to either use multiprocessing (run multiple processes instead of multiple threads) or use libraries that bypass GIL in a way it was done in the example.
I hope that now you have a better understanding of how to marry Python and C module in order to bypass some of those limitations.