I’ve recently done a pet project on Django and AWS to better get to know those 2 platforms. Unfortunately I’m unable to deliver enough tutorials to justify maintaining the entire environment, but I’m eager to share my experience, what went well, what went wrong. If you like this post, subscribe to the newsletter to keep up to date. No spam guaranteed 😉
Assumptions
What I wanted to have in the terms of the infrastructure was a frontend that would live in the same project as backend, but could be easily detached. Moreover, I wanted to be able to perform background processing. That way time consuming tasks like image processing wouldn’t affect the user experience. I also wanted to use standard SQL database. The last thing that was on my list was the ability to easily move project to a different environment. The only work I allowed was to change some environment settings and this should be enough to run project on different provider platform, local server etc. Therefore I wanted to avoid solutions like AWS Lambda (although I kinda like it). What this left me with was:
- Django with Django Rest Framework as backend – Django was responsible for rendering templates with frontend code, while DRF provided RESTful API for communication. With an opinionated framework I needed to follow its philosophy instead of reinvening the wheel with my own solutions;
- PostgreSQL running on RDS – here I went with the cheapest option, so I didn’t have read or standby replicas in case of failure;
- VueJS for frontend – I chose this framework since I was able to read half of the official tutorial and start coding;
- Celery for background processing – this solution integrates smoothly with Django and allows to easily choose message broker. So I could have Redis or RabbitMQ locally and SQS on the production. The changes were very easy (just changing some connection strings) while remaining cost efficient. On SQS you only pay for what you actually use and first 1 million requests are free making it very cheap. As compared to about 10-20 USD that I needed to pay for Redis or RabbitMQ as managed service);
- Docker – for providing the containers that I would use;
Cloud solutions used
As I’ve said I wanted a balance between learning cloud solutions and the ability to maintain independence. Therefore I used the following solutions:
- GitHub for code storage and CI pipelines with GitHub Actions. AWS provides a very easy integration. By installing an application I can configure Django deployments on AWS infrastructure;
- For Continuous Delivery I went with AWS Code Pipeline that run Code Build to build and push images to the ECR, which is a registry for Docker images.
- This pipeline would also run the deployments on ECS. Now, a few words on what ECS is. This service provides the ability to run images. Something like Kubernetes or Swarm. It provides orchestration for containers. What it does not provide is the runtime environment. To actually have “metal” to run the code you either need your own infrastructure, EC2 virtual servers or Fargate, which is a serverless solution.
- Fargate to run and scale the containers. There were 3 containers: 1 for Celery, 1 for web application, 1 for migration and copying static files (CSS, JS etc.).
- SQS to send messages from Django to Celery. I’ve also tried Elasticache with Redis, but the SQS provided simple enough integration and was way cheaper.
- RDS to run the database in a serverless manner. I didn’t go for standby replicas or read replicas due to the cost management. Choosing the PostgreSQL instead of Aurora in order to have better replication between my local environment and production environment was also an important factor. I know that Aurora can provide compatibility with PostgreSQL, but I just wanted a tried out solution.
- SES for email sending.
- Cloud Watch for monitoring.
- Other services like Application Load Balancer.
- Rollbar for monitoring. Again – super smooth integrations, it could even create tickets whenever needed. For example this ticket was created on some error in the app.
How was the Django app run on AWS?
The deployment pipeline was following:
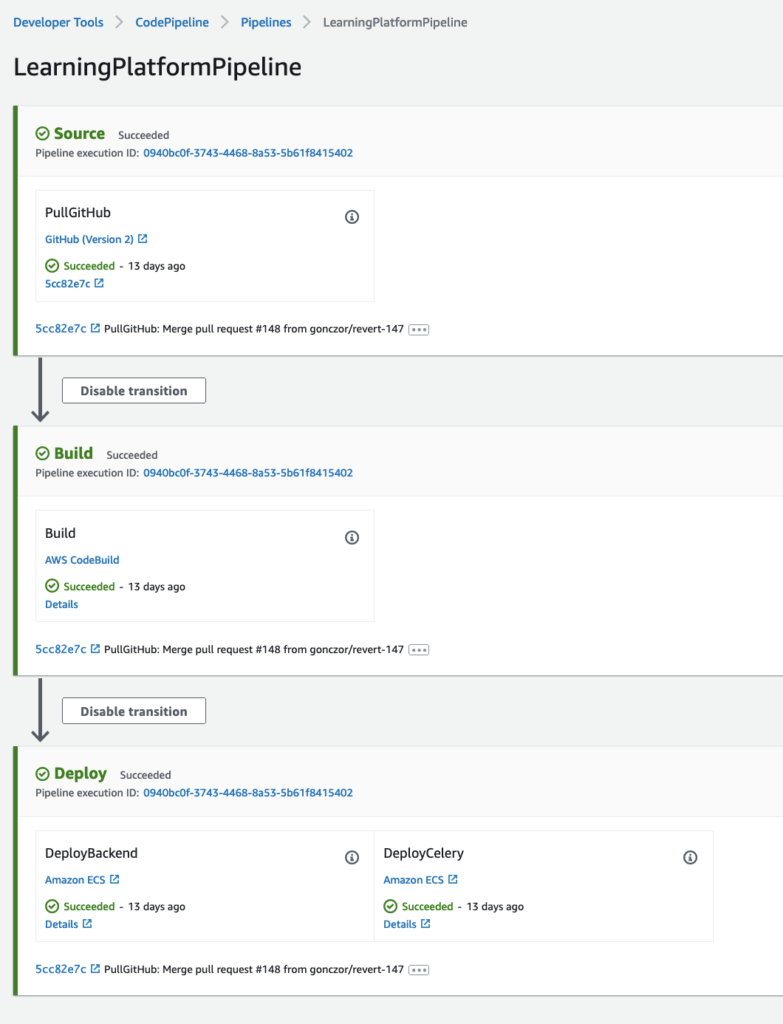
This landed on the ECS:
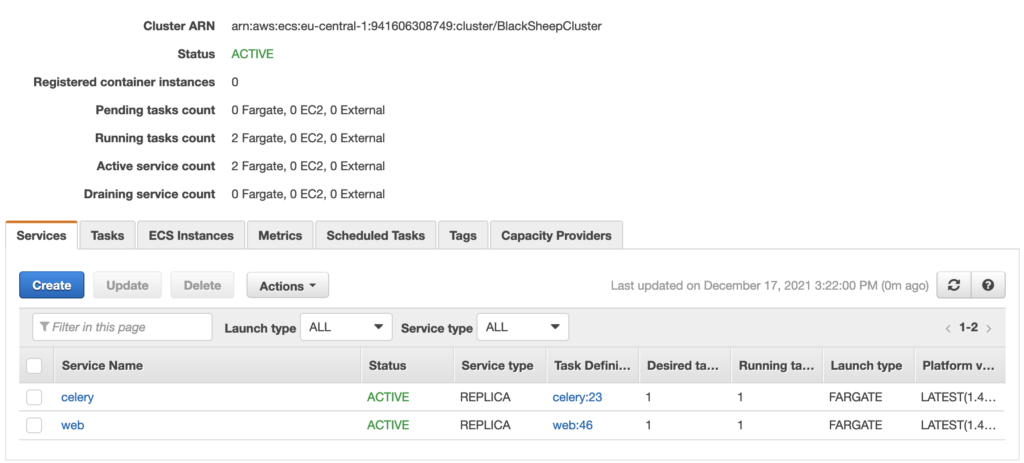
For example the web service consisted of web container and migration one which copied static files and run database migrations.

Code
What I wanted to have was: user management – a user should be able to create an account with email and confirm the creation. There were various permissions among the system, so for example regular user would be able to create and delete own comments, but also a moderator role could exist that would be able to delete all comments. In the center there were courses that the user could sign up to. Those were split into sections containing lessons. A lesson was a polymorphic entity that could be a lesson or a quiz.
General layout in Django
I went with the typical Django code organization – reusable apps (that are sometimes called components in other technologies). A typical app consisted of a model representing the database entity, url namespace, views, serializers and unit tests. Between Django and Celery I placed a message broker and both could use the database. Only Django had the access to the world (although in production I restricted it to the communication with the load balancer).
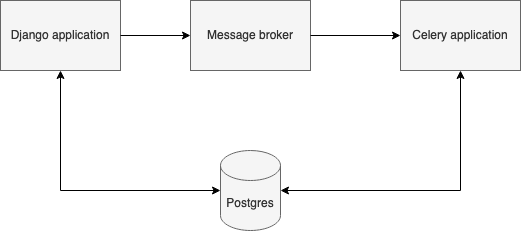
The separation of concerns
In order to provide a separation between models that interacted the database and the views in cases like exception handling I tried to create custom exceptions whenever applicable. The example is below (Django ORM is an active record type of orm, so the complete() method is directly on the model.
class BaseLesson(PolymorphicModel):
# ...
def complete(self, user: User):
try:
CompletedLesson.objects.create(lesson=self, user=user)
except IntegrityError as e:
raise ProcessingException(detail="Already marked as complete.") from e
And this was handled by the view:
class LessonViewSet(ModelViewSet):
# ...
@action(
detail=True,
methods=["PATCH", "POST"],
url_path="mark-as-complete",
url_name="mark_as_complete",
)
def mark_as_complete(self, request: Request, pk: int) -> Response:
lesson = self.get_object()
try:
lesson.complete(user=self.request.user)
except ProcessingException as e:
raise ProcessingApiException(detail=e.detail) from e
return Response(status=status.HTTP_204_NO_CONTENT)
The handling of AWS – specific code in Django
Entire code that I needed to write to make use of the AWS features was places in the aws package. I made sure that I wouldn’t need to change application logic when I decided to get rid of any of those features.
Another feature I created was the collection of secrets stored in AWS SSM. For local development I simply pulled them from the environment variables. The choice was made based on the value of DEBUG environment variable and the factory pattern was used
from aws.secrets_retriever import SSMSecretsRetriever
from .base_retriever import BaseSecretsRetriever
from .environment_variables_retriever import EnvRetriever
class RetrieverFactory:
def __init__(self, is_prod: bool):
self._is_prod = is_prod
def create_retriever(self) -> BaseSecretsRetriever:
if self._is_prod:
return SSMSecretsRetriever()
else:
return EnvRetriever()
The SSM retriever was:
class SSMSecretsRetriever(BaseSecretsRetriever):
def __init__(self):
region_name = "eu-central-1"
self._common_prefix = "/BlackSheepLearns/dev/"
# Create a Secrets Manager client
session = boto3.session.Session()
self._ssm_client = session.client(service_name="ssm", region_name=region_name)
def retrieve(self, name: str) -> str:
logging.info("Retrieving secret: %s", name)
return self._ssm_client.get_parameter(Name=self._common_prefix + name, WithDecryption=True)[
"Parameter"
]["Value"]
Since the courses included videos and images I needed to store them somehow. As I’ve already mentioned I used the S3 for the media and static files storage. The static files had public read permission, whereas in order to serve media files I utilized something called signed URLs. The idea is that the Django application authorizes the client to perform certain operations on the file stored in the S3. I made sure that only GET operations were allowed. The benefit was that I did not put load on my application when serving resource consuming files like videos.
class BlackSheepS3MediaStorage(S3Boto3Storage):
location = "media/"
def url(self, name, parameters=None, expire=600, http_method="GET"):
params = {
"Bucket": settings.AWS_STORAGE_BUCKET_NAME,
"Key": f"{self.location}{name}",
}
resp = self.bucket.meta.client.generate_presigned_url(
"get_object", Params=params, ExpiresIn=expire, HttpMethod=http_method
)
return resp
Tests
I made sure that I test the code properly. To do so I wrote tests that checked whether the endpoints returned data in the proper format, users could perform only specific operations and one test that I’m a bit proud of that made sure that I limited the database queries:
def test_retrieve_assigned_number_of_queries(self):
course_section = CourseSection.objects.create(course=self.course, name="test section")
Lesson.objects.create(course_section=course_section, name="test_lesson")
CourseSignup.objects.create(user=self.user, course=self.course)
self.client.force_authenticate(self.user)
# previously there were 5
with self.assertNumQueries(4):
r = self.client.get(reverse("courses:course-retrieve-assigned", args=(self.course.id,)))
self.assertEqual(r.status_code, status.HTTP_200_OK)
Tests were triggered automatically on the GitHub. There were 3 tests:
- linting;
- Unit and functional tests;
- Django doctor code reviews.

Django doctor was launched automatically and tests and linting was configured by me.
name: Test
on: push
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Copy configs
run: cp .env.example .env
- name: Build Image
run: docker-compose build web
- name: Wake up databases
run: docker-compose up -d db redis
- name: Test
run: docker-compose run web python manage.py test --parallel
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Copy configs
run: cp .env.example .env
- name: Build Image
run: docker-compose build web
- name: Isort
run: docker-compose run web isort --check .
- name: Black
run: docker-compose run web black --check --diff .
- name: MyPy
run: docker-compose run web mypy .
BTW, I simply love how simple this was.
Image handling
One suprisingly tricky part was image resizing. The course had an image assigned and I wanted to make a copy of this image in small size that would fit my UI. For this I used Celery that received the ID of the course, which needed to have the image resized. I also made signals responsible for other image operations like deleting unused ones.
In models I defined the hooks:
post_save.connect(cover_image_resize_callback, sender=Course) post_delete.connect(delete_cover_images, sender=Course) pre_save.connect(delete_images_if_changed, sender=Course)
And the callbacks:
def cover_image_resize_callback(sender: "Course", *args, **kwargs):
resize_course_cover_image.apply_async(args=[kwargs["instance"].id])
# Extracted code to make testing easier.
def _delete_cover_image(instance: "Course"):
instance.cover_image.delete(save=False)
instance.small_cover_image.delete(save=False)
def delete_cover_images(sender: "Course", instance, *args, **kwargs):
_delete_cover_image(instance)
def delete_images_if_changed(sender: "Course", instance, *args, **kwargs):
from .models import Course
if instance.pk is None:
return
old_course = Course.objects.get(pk=instance.pk)
if instance.cover_image.name != old_course.cover_image.name:
_delete_cover_image(old_course)
The code responsible for the resizing was a bit tricky since I had to avoid some corner cases (like the situation when I did not update the course image). Another example was to disconnect signals in order to avoid an infinite loop that would continuously update the model:
import io
from typing import TYPE_CHECKING
from celery import shared_task
from PIL import Image
if TYPE_CHECKING:
from courses.models import Course
@shared_task
def resize_course_cover_image(course_id: int):
from django.db.models import signals
from courses.models import Course
from courses.signals import cover_image_resize_callback
course = Course.objects.get(id=course_id)
if _does_not_have_image(course):
return
if not _image_changed(course):
return
try:
# Do not call signal again
signals.post_save.disconnect(cover_image_resize_callback, sender=Course)
with Image.open(course.cover_image) as original_image:
new_width, new_height = _get_small_size(original_image)
new_image = original_image.resize((new_width, new_height))
_save_resized(new_image, course)
except Exception:
raise
finally:
signals.post_save.connect(cover_image_resize_callback, sender=Course)
def _get_small_size(original_image: Image) -> tuple[int, int]:
original_height = original_image.height
original_width = original_image.width
new_width = 200
new_height = int((new_width / original_width) * original_height)
return new_width, new_height
def _save_resized(new_image: Image, course: "Course"):
output = io.BytesIO()
new_image.save(output, format="JPEG")
output.seek(0)
name_parts = course.cover_image.name.split("/")[-1].split(".")
name = "".join(name_parts[:-1]) + "_small" + "." + name_parts[-1]
course.small_cover_image.save(name, output, save=False)
course.save()
def _does_not_have_image(course: "Course") -> bool:
return course.cover_image.name == ""
def _image_changed(course: "Course") -> bool:
"""
The small cover image has the same name appended by _small suffix.
If the name of the small image name does not start with the full
image name, it means that a change has taken place.
"""
if course.small_cover_image.name == "":
return True
full_image_base_name = course.cover_image.name.split("/")[-1].split(".")[0]
small_image_base_name = course.small_cover_image.name.split("/")[-1].split(".")[0]
return not small_image_base_name.startswith(full_image_base_name)
Frontend
This is probably the worst and most boring part. I used VueJS scripts that I attached to Django templates rendered by the backend. For example:
const HelloVueApp = {
el: '#vueApp',
methods: {
async listCourses(){
const response = await axios.get(
'/api/v1/courses/',
{
headers: {
Authorization: 'Token ' + window.localStorage.token
}
}
);
this.courses = response.data.results;
await this.listOwnCourses();
},
// ...
},
data() {
return {
courses: [],
ownCourses: [],
courseDetails: {},
displaySignup: false,
signupToast: document.getElementById('signupToast')
}
},
mounted() {
this.listCourses();
}
}
const app = Vue.createApp(HelloVueApp)
app.config.errorHandler = (error, vm, info) => {
console.log(error);
};
app.mount('#courses-list');
And the template for rendering:
{% extends 'base.html' %}
{% block content %}
{% verbatim %}
<div id="vueApp">
<div class="container">
<div class="row" id="courses-list">
<div class="col-lg-2">
<div class="m-2 border rounded">
<div class="p-2 text-center fw-bold">
Available courses:
</div>
<div v-for="course in courses">
<div class="text-center course-element" v-on:click="getCourseDetails" :data-id="course.id">
{{ course.name }}
</div>
</div>
</div>
<div class="m-2 border rounded">
<div class="p-2 text-center fw-bold">
Your courses:
</div>
<div v-for="course in ownCourses">
<div class="text-center course-element" v-on:click="redirectToDetails" :data-id="course.id">
{{ course.name }}
</div>
</div>
</div>
</div>
<!---
And so on...
--->
{% endverbatim %}
{% endblock content %}
{% block scripts %}
{% load static %}
<link rel="stylesheet" href="{% static 'css/courses.css' %}">
{% if running_prod %}
<script src="https://unpkg.com/vue@3.2.6/dist/vue.global.prod.js"></script>
{% else %}
<script src="https://unpkg.com/vue@3.2.6"></script>
{% endif %}
<script src="{% static 'js/axios.min.js' %}"></script>
<script src="{% static 'js/courses.js' %}"></script>
{% endblock scripts %}
Troubles (both with Django and AWS)
There were several things that didn’t go as I expected. For example when I was uploading large files (1.4 GB) I got 502 responses. Nothing got logged and I was stuck. When I tried to reproduce the issue with EC2 instead of Fargate everything worked fine. From what I was told by a friend this might be an issue with timeouts set by the serverless solution.
There is also lack of certain panels, for example the user can’t change their own account details. I simply didn’t have time to handle this.
The secret management was another thing I guess could do better. For example I think that I could pass the secrets directly as environment variables instead of calling the AWS SDK to pull and decrypt them. Again – lack of time to do this properly.
How efficient it was?
I’ve tested the above mentioned environment using Apache Benchmark. I used single endpoint that would require authentication, and performed read operations to the database. For single concurrent request and 1000 requests in total the response times were following:
➜ ab -n 10000 -c 1 -H 'Authorization: Token <REDACTED>' https://courses.blacksheephacks.pl/api/v1/courses/4/retrieve-assigned/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking courses.blacksheephacks.pl (be patient)
Completed 1000 requests
^C
Server Software: gunicorn/20.0.4
Server Hostname: courses.blacksheephacks.pl
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
Server Temp Key: ECDH P-256 256 bits
TLS Server Name: courses.blacksheephacks.pl
Document Path: /api/v1/courses/4/retrieve-assigned/
Document Length: 528 bytes
Concurrency Level: 1
Time taken for tests: 159.050 seconds
Complete requests: 1025
Failed requests: 0
Total transferred: 828200 bytes
HTML transferred: 541200 bytes
Requests per second: 6.44 [#/sec] (mean)
Time per request: 155.171 [ms] (mean)
Time per request: 155.171 [ms] (mean, across all concurrent requests)
Transfer rate: 5.09 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 72 89 42.2 85 1094
Processing: 49 65 56.6 53 860
Waiting: 49 65 56.6 53 860
Total: 122 155 73.8 138 1146
Percentage of the requests served within a certain time (ms)
50% 138
66% 141
75% 143
80% 145
90% 160
95% 264
98% 396
99% 503
100% 1146 (longest request)
1 second the longest request with median of 10% of this time. For 10 concurrent requests:
➜ ab -n 10000 -c 10 -H 'Authorization: Token <REDACTED>' https://courses.blacksheephacks.pl/api/v1/courses/4/retrieve-assigned/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking courses.blacksheephacks.pl (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: gunicorn/20.0.4
Server Hostname: courses.blacksheephacks.pl
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
Server Temp Key: ECDH P-256 256 bits
TLS Server Name: courses.blacksheephacks.pl
Document Path: /api/v1/courses/4/retrieve-assigned/
Document Length: 528 bytes
Concurrency Level: 10
Time taken for tests: 260.026 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 8080000 bytes
HTML transferred: 5280000 bytes
Requests per second: 38.46 [#/sec] (mean)
Time per request: 260.026 [ms] (mean)
Time per request: 26.003 [ms] (mean, across all concurrent requests)
Transfer rate: 30.35 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 71 112 146.8 87 2202
Processing: 49 147 73.1 132 814
Waiting: 49 146 73.0 131 814
Total: 128 259 167.1 220 2289
Percentage of the requests served within a certain time (ms)
50% 220
66% 233
75% 249
80% 259
90% 336
95% 481
98% 704
99% 1328
100% 2289 (longest request)
Twice that much for median response, much longer longest request. And for 10000 total requests while making 100 concurrent requests:
➜ ab -n 10000 -c 100 -H 'Authorization: Token <REDACTED>' https://courses.blacksheephacks.pl/api/v1/courses/4/retrieve-assigned/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking courses.blacksheephacks.pl (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software: gunicorn/20.0.4
Server Hostname: courses.blacksheephacks.pl
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
Server Temp Key: ECDH P-256 256 bits
TLS Server Name: courses.blacksheephacks.pl
Document Path: /api/v1/courses/4/retrieve-assigned/
Document Length: 528 bytes
Concurrency Level: 100
Time taken for tests: 246.594 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 8080000 bytes
HTML transferred: 5280000 bytes
Requests per second: 40.55 [#/sec] (mean)
Time per request: 2465.944 [ms] (mean)
Time per request: 24.659 [ms] (mean, across all concurrent requests)
Transfer rate: 32.00 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 70 134 199.2 88 2439
Processing: 73 2319 324.8 2297 3650
Waiting: 56 2318 324.8 2296 3650
Total: 183 2453 343.2 2392 4717
Percentage of the requests served within a certain time (ms)
50% 2392
66% 2481
75% 2556
80% 2633
90% 2858
95% 3081
98% 3509
99% 3645
100% 4717 (longest request)
At this point I could tell that using the website was noticeably slower. 4 seconds for the longest process and 2 seconds for median are way above any acceptable levels. If I reached this amount of traffic I would definitely require some kind of autoscaling based on response times or CPU utilization (the latter is easier to integrate). You can observer the deterioration in cloud watch below.

Later on I’ve played around with autoscaling based on the CPU utilization, however, I didn’t collect the metrics for this.
Summary of my Django and AWS adventure
I believe this was an extremely valuable lesson. I have got a better insight both into Django and AWS.
All in all I think that the results and price/effect ratio are reasonable for small traffic and single developer, who can’t devote much time to maintaining the infrastructure. What’s also worth mentioning is that although I remained within the free tier I got a reasonable database latency. For production-level I would definitely go with something bigger and providing a failover, but as it turns out for hobby projects this is enough.
This project is under the GPL licence, so if you would like to set up your own Django project on AWS, you’re free to use it. The only real restriction is that you also make it open source. If you liked this post, subscribe to the newsletter. I promise only posts on merits.